If you spend any amount of time working with Postgres, it’s likely that at some point you’re going to wonder why it is not using an index that you think it should be.
Unlike some databases, you can’t force PostgreSQL to use a specific index, but there are several things you can do to work out what’s going on.
If you’re somewhat new to Postgres, I hope that going through these will be interesting, as well as being useful next time you see an issue like this.
I’ll be assuming a basic familiarity with query plans (using EXPLAIN) and Postgres indexing, but honestly not much.
The two main reasons
There are two main reasons that Postgres will not use an index. Either it can’t use the index, or it doesn’t think using the index will be faster.
Working out which of these is the reason in your case is a great starting point.
Sadly, we can’t tell from a single query plan which case we’re seeing, but through some investigating via multiple query plans, we can work out what’s going on.
The reasons that Postgres can’t use an index are more straightforward, and it’s also the easier of the two to rule out, so let’s start there.
Checking whether Postgres can use the index
There are a few reasons Postgres won’t use a seemingly perfect index for a query.
For example:
- The index doesn’t exist (oops)
- A function is preventing its use
- A datatype mismatch is preventing its use
- The index type doesn’t support the operator in the query
To start with, you can try to disprove you’re in this category of issue by getting a query plan that does use the index.
As I alluded to earlier, some other databases have a “query hints” feature that allows you to (pretty much) force the use of a specific index. But since PostgreSQL does not have such a feature, we’ll steer clear of that holy war and look at what we can do instead.
Postgres has several parameters that let us temporarily discourage the planner’s choice of certain operations. If you want to encourage an index scan in place of a sequential scan, you can try:
set enable_seqscan = off;
This does not, as the name might suggest, completely disable sequential scans, but rather discourages them by making the planner think they’d be a LOT more expensive than they really would be.
As such, if after setting this to off, you still get a Seq Scan, there’s a really good chance that Postgres can’t use the index you want, and you’re seeing that category of issue. If, however, it does now use the index you’d hoped, you now know that it is choosing not to.
Similarly, if Postgres is picking a different index instead of the index you think would be optimal, then this trick to make indexes invisible (to drop an index, run your query, and then rollback – all inside a transaction) shared by Haki Benita is a nice way to test this, in a non-production environment of course. Again, whether the query plan changes or not gives you a very good signal as to which category of problem you have.
If Postgres can’t use the index
If you think you’re in the boat of Postgres not being able to use the index, it is first worth checking that the index you’re expecting Postgres to use actually exists (in the environment you’re testing in). If it doesn’t, please believe me that you are not the first, and won’t be the last, to be in this situation! And at least you now have a simple solution.
Assuming the index does exist, though, the next step is to look at its definition. This will be helpful for the next two checks we’ll do.
Functions
If your query has a function on the data involved, your index will likely need to match it to get used. For example, consider a query like:
select * from t where lower(email) = ‘michael@pgmustard.com’;
Postgres won’t use an index on “email” for this, even if it theoretically could.
To quickly test if this is the issue you’re seeing, you can request the query plan for the query without the function, for example:
explain select * from t where email = ‘michael@pgmustard.com’;
If you see it is now using your index, and this is how you commonly query that column, you may wish to add a functional index. For example, in this case:
create index i on t (lower(email));
Similarly, you might see this when doing arithmetic on a column. For example, the following query would require an index on “(column + 1)”:
select * from t where column + 1 = 10;
Whereas the equivalent query below would be able to use an index on “column”:
select * from t where column = 10 - 1;
In cases like this, if you are able to change the query, that is normally the better solution.
Datatype mismatches
Earlier, I also mentioned datatype mismatches. You might spot these in the query plan through datatype casting (the :: characters). Postgres can handle some of these without issue, eg varchar to text, but some casts will result in an index not being used.
Here is a contrived example:
explain select * from t where id = 100::numeric;
The explicit cast prevents use of my index, resulting in this query plan:
Seq Scan on t (cost=0.00..2041.00 rows=500 width=10) Filter: ((id)::numeric = '100'::numeric)
To test whether this is the issue, you can try explicitly casting to the column’s datatype in your query, or avoiding casting being added by the application (eg via an ORM).
Operators not supported by the index type
The final example in our list was the index type not supporting the operator in the query. Here is an example that won’t use a B-tree index on “email”, since it uses ILIKE:
select * from t where email ILIKE ‘michael@pgmustard.com‘;
Thanks to Creston Jamieson for the suggestion to add this last one!
If Postgres can use the index, but doesn’t think it will be faster
If you’ve determined that Postgres can use the index, but is choosing not to, then this next section is for you.
There are usually several ways Postgres can get the results of a given query. As such, before executing a query, the planner will estimate the “cost” of different options, and pick the plan with the lowest cost in the hope that it will be the fastest way of executing that query. It’s important to note that these costs are in an arbitrary unit, where higher numbers are a predictor of higher execution times, so it’s the relative numbers that matter, not the absolutes.
As such, if Postgres chooses not to use your index, it is likely that it is calculating the cost of that query plan to be higher than the one it has chosen.
We can verify this by using the tricks mentioned in the previous section, like enable_seqscan = false, or hiding other indexes, and comparing the estimated costs of the different query plans.
The next step is to check whether the execution time of the plan that uses the index is actually faster, or not. You may wish to run such tests a few times, to ensure the cache is warm. If the query using the index isn’t faster, you are looking at a case where the planner has correctly chosen not to use your index.
At this point, it is worth noting that the Postgres planner will try to optimize for execution time, rather than efficiency (eg blocks of data read). Although these usually go hand in hand, it is a subtle distinction worth bearing in mind.
There are a few (normally good) reasons for Postgres choosing a sequential scan even when it could use an index scan:
- If the table is small
- If a large proportion of the rows are being returned
- If there is a LIMIT clause and it thinks it can abort early
If none of these are the case, you may wish to skip ahead to the cost estimation section.
If the table is small
If a table is small (very roughly 100 rows or fewer), Postgres may estimate that it will be faster to read the table sequentially and filter out rows as needed, even for highly selective queries.
For example, in pgMustard we show scans on small tables as an anti-tip (scoring 0.0 out of 5.0 for index potential):
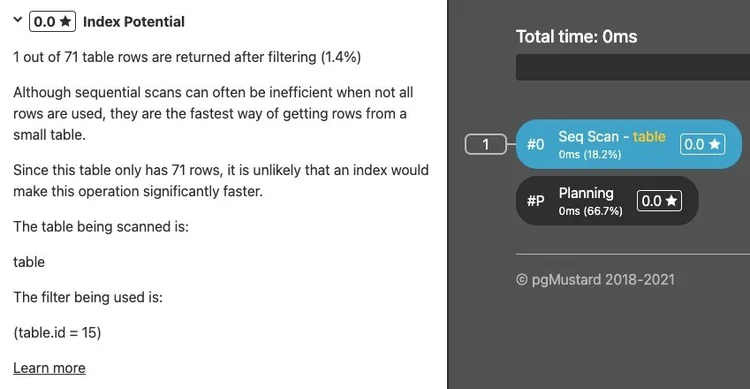
If this is a test environment, and you have a lot more data in production, you may need to consider testing on a more realistic dataset.
On the other hand, if this is a realistic dataset already, and it would in fact have been significantly faster to use an index, you may wish to look into the “suboptimal configuration” section below.
If a significant proportion of the rows are being returned
Another case where Postgres will choose to do a sequential scan over an index scan is when a significant proportion of the table is being returned. The exact proportion of what will count as significant will vary depending on the data and cost parameters, but here is an example (with default configuration) of it doing so to return 30% of the data:

Similarly to the small table case, in pgMustard, you will see cases like this as an “index potential” anti-tip, with details about the proportion of rows being returned.
Again, if you work out that (for your query and hardware) it would have been faster to use an index, a good next step is to look into the configuration section below.
Limit clauses
The third case I mentioned above can happen when you have a low LIMIT clause (relative to the total number of rows), and the planner believes it is likely to find enough qualifying rows quickly, allowing it to abort early.
This optimization is a double-edged sword, leading to very fast queries when the planner is correct, and very slow queries when it is wrong. The guide to using EXPLAIN in the PostgreSQL documentation includes a nice LIMIT example, and Christophe Pettus, CEO at PostgreSQL Experts Inc, also succinctly described the potential dangers of using LIMIT in a recent Twitter thread.
As well as avoiding the use of LIMIT when you don’t need it, you can also help the query planner estimate row counts more accurately. Luckily, we’re just about to go into how to do that!
Cost estimation
Naturally, a lot of the times the query planner chooses a suboptimal query plan, it’ll boil down to inaccurate cost estimation.
There are a few ways Postgres can end up badly estimating the overall cost, but the biggest two categories of issue are:
- Its row count estimates are way off
- Its cost constants are configured suboptimally
In my experience, bad row count estimates have been the more common of the two, so let’s start there.
Bad row count estimates
The query planner estimates the number of rows each operation will return (mostly) using statistics it has gathered. It keeps these statistics up to date via ANALYZE – not to be confused with the EXPLAIN parameter of the same name.
These estimates can end up way off if the data changes dramatically before it gathers new statistics, or if any of its assumptions are bad for a different reason. Naturally, these bad estimates can affect things that are very important for performance; like join order, join strategy, and of course whether (and how) it uses indexes.
Bad estimates can sometimes be quickly resolved by manually running ANALYZE on the tables involved. If this helps, then you should look into preventing recurrences by ensuring ANALYZE runs more regularly going forwards (eg via autovacuum).
If one of the columns involved has a skewed distribution you may see better estimates after increasing the statistics target.
Another common source of bad estimates is that Postgres assumes that two columns are independent by default. If that’s the root cause, we can ask it to gather data on the correlation between two columns (in the same table, at least) via multivariate statistics.
If this section felt a little rushed, you might like our more in depth post dedicated to bad row count estimates.
Suboptimal configuration
Last, last but certainly not least, we come to planner cost constants. These are used by the query planner to determine the cost of each operation, and subsequently the query plan as a whole.
Cost configuration is a big a topic, so we’ll take a look at the basics and a couple of resources to learn more.
On the topic of index use, if you’re still seeing a Seq Scan instead of the Index Scan that would be faster, then a good parameter to check is random_page_cost:
show random_page_cost;
By default, this is set to 4.0, which is 4x higher than the seq_page_cost of 1.0. This ratio made a lot of sense for spinning disks, but assuming your system has SSDs, you may wish to look into a lower setting. It is not uncommon to see modern PostgreSQL setups with random_page_cost set to 2.0, 1.5, or even 1.1, but as ever, please do test carefully before changing this on production.
To test whether it helps, you can change a parameter like this in a session and use EXPLAIN ANALYZE to see whether it results in a faster query plan being chosen.
Another common cost-related reason for Postgres favouring a Seq Scan over an Index Scan is if it is parallelizing operations. To quickly test this, you can disable parallel execution locally and re-request the query plan, for example via:
set max_parallel_workers_per_gather = 0;
There are many other cost-related configuration parameters that you may find beneficial to tune. The query planning section of the PostgreSQL docs contains a useful list, and you can then look up each of them on the postgresqlco.nf website, which includes advice, courtesy of Josh Berkus’ excellent annotated.conf, as well as useful information and links courtesy of the team at Ongres.
In summary
So in summary, our first step was to check whether Postgres could use the index.
If it couldn’t, we double-checked it actually existed, before seeing whether a function or datatype mismatch could be the problem.
If it could, we compared the execution time to make sure it wasn’t right all along, then looked into the row count estimates and planner cost constants, looking for ways to help it calculate the relative costs more accurately.

Next steps
If, after this, you’re still facing an issue, both the PostgreSQL Wiki and Stack Overflow have good guides for troubleshooting performance problems, asking for help, and reporting bugs.
If you do get to the bottom of your issue, it’d be great to hear the details.